강화학습 Reinforcement Learning
강화학습은 머신러닝의 한 영역이다.
Agent는 환경에 대한 State 정보를 받고 그에 따른 Action을 취한다. Action에 대한 Reward를 받고, 그 행동에 대해 평가를 하며 어느 방향으로 행동하는 것이 더 큰 Rewrad를 받을지 학습한다.
머신러닝의 종류는 다음과 같이 볼 수 있다.
- supervised learning
- unsupervised learning
- reinforcement learning
(비)지도 학습은 사람이 데이터 셋을 관리하고 입력해야 하기 때문에 많은 시간과 비용이 필요하다. 그리고 목표로 하는 값은 결국엔 사람의 결과값을 흉내 내는 것이기 때문에 사람보다 더 뛰어난 성능을 낼 것이라고 기대하기 어렵다.
Markov Decision Process (MDP)
Markov property는 현재에 대한 조건부로 과거와 미래가 서로 독립인 확률과정이다. 미래의 S(state)와 R(reward)로 인해 현재의 S와 A(action)가 영향을 받을 때를 의미한다. 미래를 유추할 때, 오직 현재의 값만이 쓸모가 있으며 과거의 값들은 아무런 추가 정보를 제공하지 않는다.
식에서의 p는 MDP의 kernel(커널)이라고 한다.

Policy
Policy는 input으로 현재 state를 받고, output으로 어떤 action을 내보낼지 확률로 주어지는 것이다.
Trajectory = (S₀, A₀, R₁, S₁, A₁, R₂, S₂, A₂ ... )
Kernel p는 변화된 상황, 리워드에 대한 것을 나타낸다. (R₁, S₁ / R₂, S₂)
MDP의 최종 목표는 축적된 reward의 값이 최대가 되게 하는 optimal 한 policy를 찾는 것이다.
- deterministic : 어떤 input에 대해 확정적으로 output을 결정하는 경우
- stationary : 시간에 따라서 output이 변하지 않는 경우
- nonstationary : 시간에 따라서 output이 변하는 경우
reward의 요소에는 discount cumulated reward가 자주 쓰인다. 이는 시간에 대한 가중치를 부여하는 reward의 요소이다.
Discount factor γ는 0과 1사이의 수로, 1에 가까울수록 미래에 대한 가치를 길게 본다.

E[ ] 괄호 안에 있는 식을 Gt, return이라고 부르며 어떤 reward를 받았는지 random variable로 표현한 것이다.
Bellman Equation
value function을 다음 function에 대해서 정리를 해보면, S1에서 다음 S2로 가는 과정에는 R을 한번 거치므로, discount factor를 곱한 값으로 나타낼 수 있으며 이는 다음 S에도 적용이 되는 반복적인 특징을 가지고 있다. 이를 식으로 표현한 것이 Bellman Equation 이다.


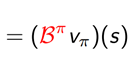
Bπ를 Bellman operator로 정의한다. 이는 input, output을 모두 함수로 갖는 operator이다. 함수에서 함수로의 mappong표현이 가능한 이유는 이 식에서 인자로 state와 value(vπ)만을 받고, 나머지는 MDP parameter에 의해서 결정되기 때문이다.
Action-Value Function (Q-function)
각 state마다 a개의 action이 존재하기 때문에 s의 a승이라는 가능한 determenisitc이 생기게 되므로 Value function 만으로 optimal 한 policy를 찾는 것은 불가능하다. 따라서 이를 효율적으로 활용하기 위해 action-value function (Q-function)을 사용하게 된다.
Q-function은 어떠한 policy가 주어지고, state와 action을 인자로 갖는다. T일 때의 인자를 집어넣은 후 t+1의 action부터는 주어진 policy를 따라가고 어떻게 되는지 관찰하는 function이다.

Value function 과는 비슷해 보이지만 At=a라는 조건이 추가된다. Q function을 통해 policy를 더 좋게 개선시키고, 더 개선된 policy 를 이용해 value function 을 다시 측정한 후, 그걸로 Q function을 계산하는 방식으로 policy를 개선시킨다. 이렇게 돌아 돌아 개선해 나가는 알고리즘을 Policy Iiteration이라고 한다.
'🐹 STUDY > Tech Stack' 카테고리의 다른 글
| 웹어셈블리(WebAssembly) (0) | 2023.03.07 |
|---|---|
| Wireless Channel Characteristics - Fading Channel (0) | 2021.12.06 |